
Open-source Large Language Models (LLMs) must catch up to their closed-source counterparts regarding capabilities and performance. Meta, which is a pioneer in making open-source LLMs available, is not giving up and is once again challenging closed counterpart models like Claude 3.5 Sonnet and GPT-4o by OpenAI. Meta is pioneering this change in open-source AI by releasing Llama 3.1 405B, the most advanced and powerful openly available model. Can this model certainly rival the top closed AI models?
Introducing the Next Open-Source AI Generation: Llama 3.1 Models
The Llama 3.1 405B is a significant advancement in open-source AI. By releasing the Llama 3.1 model with 405B parameters, Meta challenges the best-closed models in general knowledge, math, tool use, steerability, and multilingual translation. This release marks a new era of innovation and possibilities. Alongside the 405B, Meta introduces updated versions of the 8B and 70B models. These updates bring better multilingual support, a longer context length of 128K, and stronger reasoning skills. Meta’s Llama 3.1 models’ family will perform better on complex tasks like summarizing long texts, multilingual conversations, and coding help.
You can download this collection of Llama 3.1 models from llama.meta.com and Hugging Face.
Model Card: Key Highlights
The Meta Llama 3.1 is a series of pretrained generative, multilingual large language models (LLMs). Models are available in 8B, 70B, and 405B sizes. It is a brand new model series released on July 23, 2024.
Supported Languages: English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai. (I hope that one day also Polish will be available)
| Training Data | Params | Input modalities | Output modalities | Context length | Knowledge cutoff |
|---|---|---|---|---|---|
| A new mix of publicly available online data. | 8B | Multilingual Text | Multilingual Text and code | 128k | December 2023 |
| A new mix of publicly available online data. | 70B | Multilingual Text | Multilingual Text and code | 128k | December 2023 |
| A new mix of publicly available online data. | 405B | Multilingual Text | Multilingual Text and code | 128k | December 2023 |
Training Data: Llama 3.1 was pretrained on approximately 15 trillion tokens from publicly accessible data. It utilized publicly available instruction datasets and over 25 million synthetically generated examples for fine-tuning. The cutoff of knowledge from this data is December 2023.
Model Performance and Comparisons
In subsequent sections, I will present the Llama 3.1 model series evaluation results compared to older models and leading closed-source models: GPT-4o and Claude 3.5 Sonnet. You will see the results of these models on different benchmarks. I do not describe these benchmarks in this article. If you want to learn more about benchmarks and evaluation metrics used for each benchmark, please take a closer look at the links available in the captions of presented tables and check these evaluation details.
Llama 3.1 vs. Llama 3
The Llama 3.1 series, especially the flagship 405B model, demonstrates significant advancements across various benchmarks, outperforming its predecessors and many non-open-source models. Key improvements are visible in general knowledge, reasoning, and reading comprehension tasks. Notably, the 405B model excels in benchmarks like MMLU, ARC-Challenge, and TriviaQA-Wiki, consistently leading in performance. The 3.1 updates also enhance smaller models (8B, 70B), making them highly competitive in their respective categories.
| Benchmark Category | Benchmark | Llama 3 8B | Llama 3.1 8B | Llama 3 70B | Llama 3.1 70B | Llama 3.1 405B |
|---|---|---|---|---|---|---|
| General | MMLU | 66.7 | 66.7 | 79.5 | 79.3 | 85.2 |
| MMLU-Pro (CoT) | 36.2 | 37.1 | 55.0 | 53.8 | 61.6 | |
| AGIEval English | 47.1 | 47.8 | 63.0 | 64.6 | 71.6 | |
| CommonSenseQA | 72.6 | 75.0 | 83.8 | 84.1 | 85.8 | |
| Winogrande | – | 60.5 | – | 83.3 | 86.7 | |
| BIG-Bench Hard (CoT) | 61.1 | 64.2 | 81.3 | 81.6 | 85.9 | |
| ARC-Challenge | 79.4 | 79.7 | 93.1 | 92.9 | 96.1 | |
| Knowledge reasoning | TriviaQA-Wiki | 78.5 | 77.6 | 89.7 | 89.8 | 91.8 |
| Reading comprehension | SQuAD | 76.4 | 77.0 | 85.6 | 81.8 | 89.3 |
| QuAC (F1) | 44.4 | 44.9 | 51.1 | 51.1 | 53.6 | |
| BoolQ | 75.7 | 75.0 | 79.0 | 79.4 | 80.0 | |
| DROP (F1) | 58.4 | 59.5 | 79.7 | 79.6 | 84.8 |
Llama 3.1 405B vs GPT-4o and Claude 3.5 Sonnet
The evaluation of Llama 3.1 405B across various benchmarks indicates that it performs competitively with GPT-4o and Claude 3.5 Sonnet. Llama 3.1 405B shows strong results in general tasks, particularly in the MMLU and IFEval benchmarks. The new model from Meta is slightly behind Claude 3.5 Sonnet for code-related benchmarks but close to GPT-4o or even better. In mathematical reasoning, it excels in the GSM8K benchmark but lags somewhat in the MATH benchmark compared to GPT-4o. Llama 3.1 405B also performs well in reasoning tasks, tool use, and multilingual capabilities.
| Benchmark Category | Benchmark | Llama 3.1 405B | GPT-4o | Claude 3.5 Sonnet |
|---|---|---|---|---|
| General | MMLU (0-shot, CoT) | 88.6 | 88.7 | 88.3 |
| MMLU PRO (5-shot, CoT) | 73.3 | 74.0 | 77.0 | |
| IFEval | 88.6 | 85.6 | 88.0 | |
| Code | HumanEval | 89 | 90.2 | 92 |
| MBPP EvalPlus | 88.6 | 87.8 | 90.5 | |
| Math | GSM8K (8-shot, CoT) | 96.8 | 96.1 | 96.4 |
| MATH (0-shot, CoT) | 73.8 | 76.6 | 71.1 | |
| Reasoning | ARC Challenge (0-shot) | 96.9 | 96.7 | 96.7 |
| GPQA (0-shot, CoT) | 51.1 | 53.6 | 59.4 | |
| Tool use | BFCL | 88.5 | 80.5 | 90.2 |
| Nexus | 58.7 | 56.1 | 45.7 | |
| Long Context | ZeroSCROLLS/QuALITY | 95.2 | 90.5 | 90.5 |
| InfiniteBench/En.MC | 83.4 | 82.5 | – | |
| NIH/Multi-needle | 98.1 | 100 | 90.8 | |
| Multilingual | Multilingual MGSM (0-shot) | 91.6 | 90.5 | 91.6 |
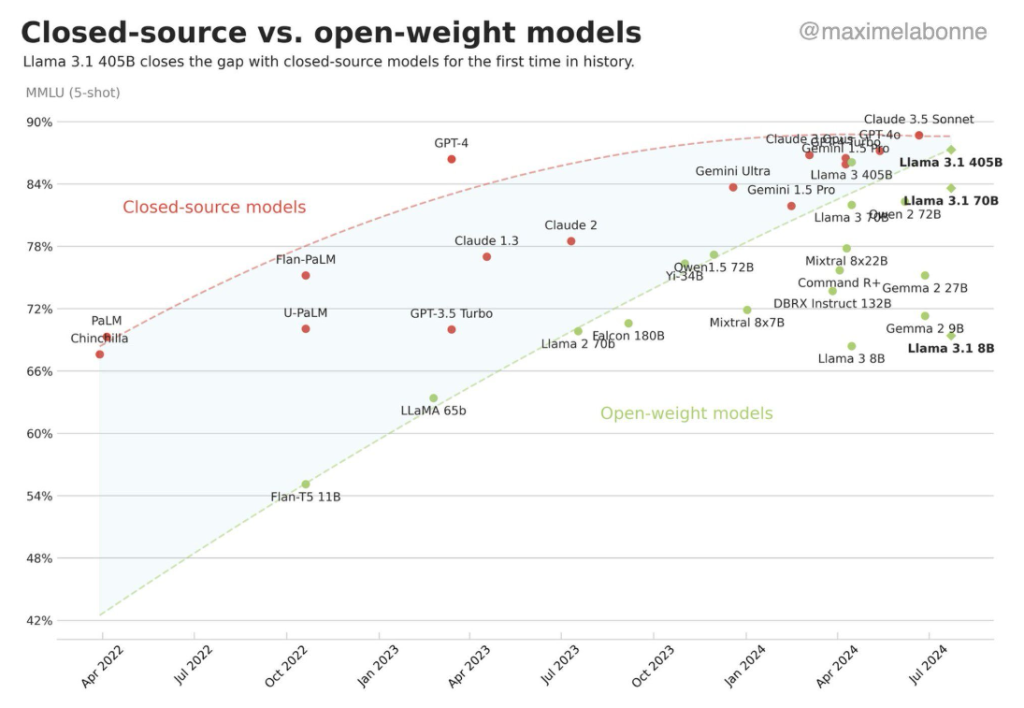
Today, on Linkedin, I also saw a fascinating figure created by Maxime Labonne. This Figure presents the result on the MMLU (5-shot) benchmark of closed-source models like GPT-4, Claude 3.5 Sonnet vs. open-weight (open-source) models like Llama 3. Maxime Labonne created this Figure a few months ago, but he updated this with the results of Llama 3.1 models. This Figure, which you can find below in this article, clearly shows that with time, open-weight models are getting closer and closer in performance to closed-weight models. I see this as a promising trend, as I strongly support open-source AI.
Conclusions
Meta’s release of Llama 3.1 represents a significant advancement in democratizing access to best-performing LLMs. By providing a powerful Llama 3.1 405B model, Meta challenges the closed-weight models of other tech giants and positions itself as a leader in the open-source AI movement. AI is changing before our eyes. It is undeniable that Llama 3.1 will further influence AI and NLP research and development. This rapid change keeps me excited and glad to be working in NLP, AI, and Data Science.
References
- Model Information Card on GitHub, Link
- Introducing Llama 3.1: Our most capable models to date; Article by Meta
- Documentation by Meta
- Photo by Willian Justen de Vasconcellos on Unsplash